Beyond the Rewrite: How CT Visa
Retires Legacy ETL on Databricks
Lakebase

Inside every Fortune 1000 data estate sits the same hidden balance sheet: thousands of Qlik scripts, Informatica mappings, SAP BODS dataflows, JPI schedules, Oracle PL/SQL packages, and T-SQL procedures, accumulated over decades. They quietly run the business and quietly drain it. License bills run into seven figures, the platform teams that maintain them are shrinking, and every cloud-modernization roadmap hits the same wall: nobody can rewrite all that legacy code fast enough to justify the move.
CT Visa changes that economics. Built by Celebal Technologies and delivered as a native Databricks App, it assesses, converts, tests, traces, and deploys legacy ETL estates as governed PySpark on Delta Lake, reasoned through Databricks AI Model Serving, governed end-to-end by Unity Catalog, with a migration control plane on Lakebase Postgres. Multi-year programs compress into single-quarter delivery; hand-rewrite waves collapse into AI-assisted review cycles, and legacy licenses start retiring on day one, not on day 365.
For the first time, the migration itself becomes a first-class Databricks data product: every project, every parsed object, every AI conversion, every lineage edge and every Job Run is persisted in governed storage and queryable from the same SQL Warehouse that already powers the rest of the business.
How CT Visa Turns a Legacy ETL Estate into a Databricks Data Product
CT Visa is an AI-powered, Databricks-native migration acceleratorthat retires legacy ETL platforms and re-lands their logic as production-grade PySpark on Delta Lake. It ships as a Databricks App, runs end-to-end inside the customer's workspace, and uses every layer of the platform: UC Volumes for source files, Databricks AI Model Serving for reasoning, Delta Lake for tables, Databricks Workflows for orchestration, Databricks SQL for validation, and Lakebase Postgres for migration metadata and audit.
No third-party SaaS, no separate data plane, no outbound connection. The platform drives every artefact through nine governed stages: create project, upload, parse, assess, convert, test, trace lineage, deploy, report, generating PySpark notebooks, validation suites, lineage graphs and Workflows jobs along the way. Nine source platforms are supported in production, covering >90% of the legacy ETL estate in a typical Fortune 1000 customer: Qlik ETL, Informatica PowerCenter, SAP BODS, SAP BW, SAP HANA Calculation Views, JPI scheduler, Oracle PL/SQL, Teradata BTEQ and Microsoft SQL Server T-SQL.
Three engineering principles separate CT Visa from the regex-and-template tools that came before:
Migration first, AI second.
Deterministic, per-platform parsers extract a clean, normalized object graph from every source artefact. Databricks AI reasons over that structured truth, never over raw script text. The result is conversion you can defend in code review, not statistical guesses you cannot debug.
Nothing leaves the tenancy
Source files persist to Unity Catalog Volumes. LLM inference can be pinned to the customer's own Databricks AI Model Serving endpoint. Converted notebooks deploy directly into the customer's workspace folders. CT Visa has no outbound data path.
Audit by construction
Every parse, assessment, conversion, test, lineage and deployment run is logged with status, duration, prompt version and approver in a Unity Catalog-governed audit trail, queryable from the same SQL Warehouse the customer already uses for everything else.
What This Looks Like at Enterprise Scale
A Tier-1 EMEA retail bank operated 800+ Informatica mappings, 1,400 SAP BODS dataflows and 600 Oracle PL/SQL packages, scheduled by JP1 across three regional data centres. The original SI proposal was a 22-month, three-team migration costed at >$18M. With CT Visa, Celebal:
- Ingested the entire 2,800-artefact estate into Unity Catalog Volumes inside 48 hours
- Produced AI-driven complexity ratings, effort estimates and a risk heatmap for every artefact in under one week
- Auto-converted 78% of mappings, dataflows and PL/SQL to PySpark on Delta Lake with zero manual rewrite
- Re-emitted the JP1 schedule graph as native Databricks Workflows jobs with retry and alerting intact
- Reduced manual conversion effort by 3.4× versus the original SI proposal
- Retired the first wave of Informatica licences four months ahead of plan, returning >$1.4M of in-year licence spend to the CFO
- Completed cut-over in 9 months versus 22 forecast, a 2.4× timeline compression
The migration became a permanent governance asset, not a one-time event the platform team has to recover from.
Why ETL Modernization Stalls: How CT Visa Breaks Each Bottleneck
The scarce-expertise bottleneck
Translating Qlik, Informatica XML, BODS ATL, Teradata BTEQ and Oracle PL/SQL to PySpark on Delta requires engineers who fluently read both sides. That talent pool is small, ageing, and expensive. CT Visa replaces direct expertise with AI translation, grounded in deterministic parsers and per-platform conversion guides, so the rate-limiting step becomes review, not rewrite.
The governance bottleneck
Legacy scripts live on developer laptops, network shares and vendor portals, all outside any enterprise catalog. CT Visa governs source artefacts the moment they are uploaded: every file in a UC Volume, every conversion to UC-grant-controlled paths, every lineage edge referenceable from the same SQL Warehouse the business already queries.
The validation bottleneck
Proving functional parity is what quietly slips every cut-over date. Manually authoring schema, data and business-logic tests for a 2,000-object estate is six person-months of error-prone work that almost always surfaces the worst regressions the week before go-live. CT Visa generates the validation suite automatically the moment a conversion completes, turning parity-testing into a continuous activity, not a last-mile fire drill.
The migration team that used to ship one wave per quarter ships one wave per month, with audit trail, lineage and validation included by construction.
Assess, Convert, Test, Lineage: The Four Engines
Assess. Each uploaded file is parsed by a platform-specific deterministic engine: Qlik .qvs into LOAD / RESIDENT / APPLY-MAP graphs, Informatica XML into source qualifiers and workflow dependencies, BODS ATL into a job-workflow-dataflow tree, HANA .hdbcalculationview into projection, aggregation and join nodes.
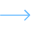
The clean object graph is handed to Databricks AI with a per-platform analysis_guide.xml prompt. The output is a 1–10 complexity rating with LOW / MEDIUM / HIGH / CRITICAL banding, an explicit risk level with named risk factors, an effort estimate in person-hours, and an AI Automation Score: the single number every CFO and CIO wants to see before signing the SoW.
Assessment view — Databricks AI rates complexity, estimates effort, flags risk and summarizes business logic, in seconds.
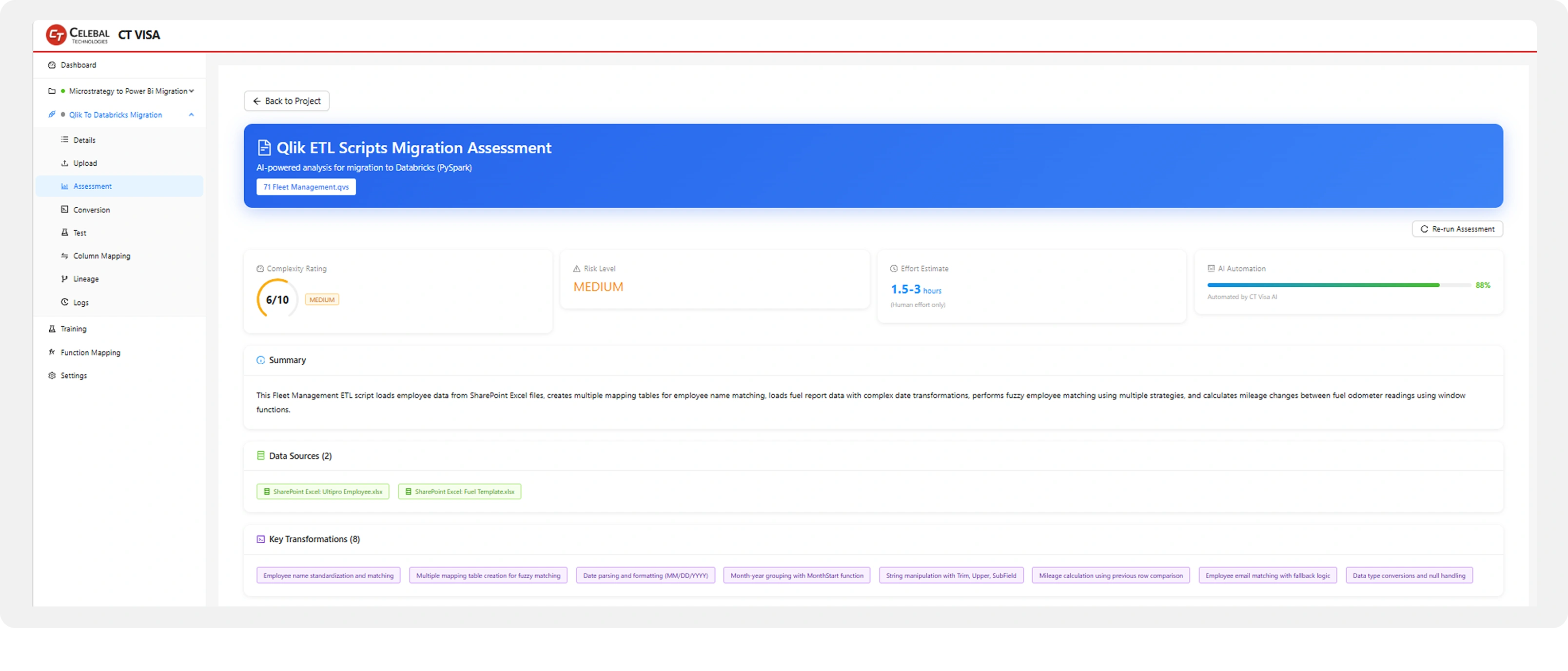
Convert. Every conversion is grounded in the parsed object graph plus a per-platform conversion_guide.xml. The output is Spark code indistinguishable from what a senior Databricks engineer would write: Qlik incremental loads become Delta MERGE INTO with explicit upsert keys; Teradata QUALIFY ROW_NUMBER() becomes Spark window functions with the same partition/order semantics; performance hints including OPTIMIZE ... ZORDER BY, Liquid Clustering and broadcast hints are emitted automatically based on the source's access patterns.
Chunked conversion services handle 1,000+ line BODS dataflows while preserving logical fidelity across boundaries. Every conversion ships with a conversion-notes log and a manual-change list so reviewers see exactly what the AI changed and what still needs human touch.
Conversion view — Source on the left, PySpark on Delta on the right, conversion notes underneath.
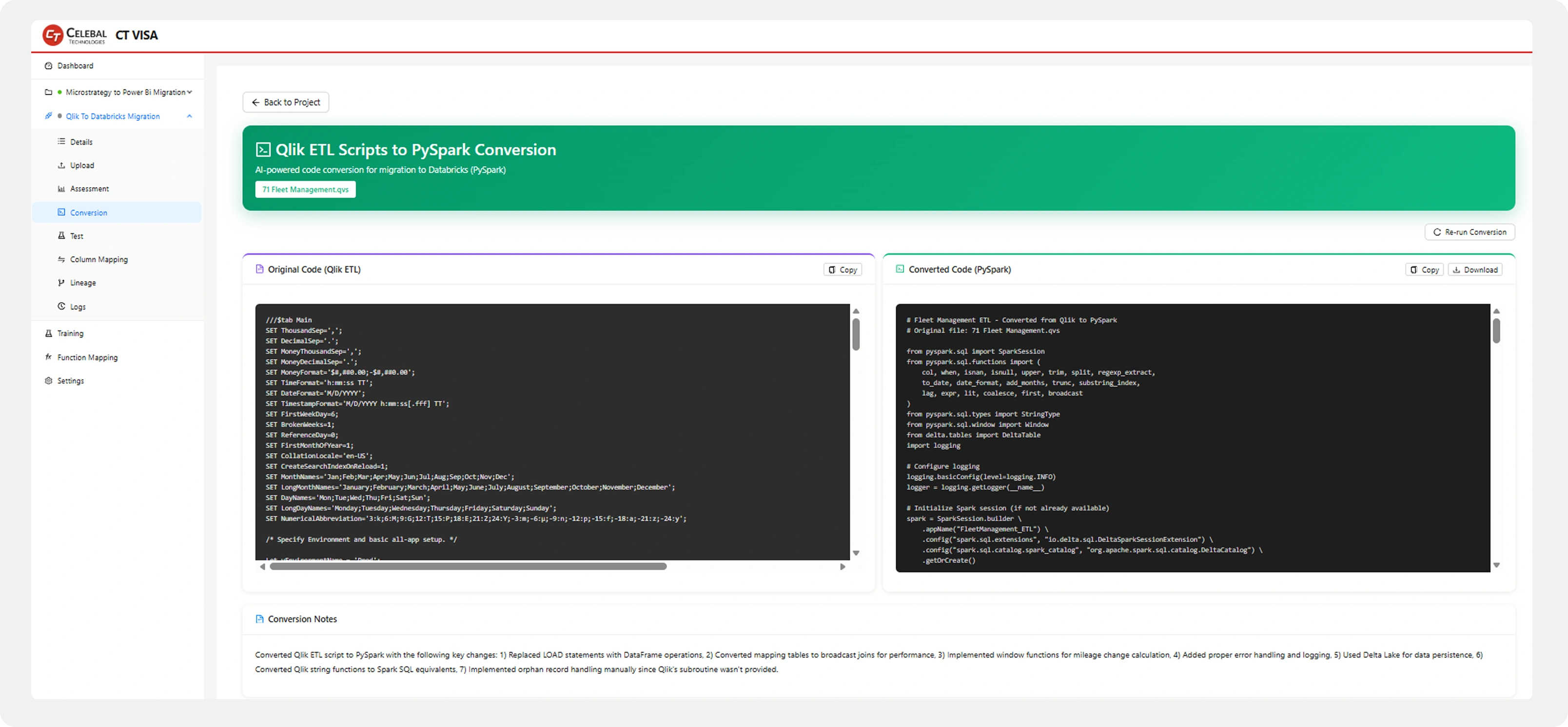
Test. For every converted artefact, the Test view generates 10–20 executable test cases per script across five buckets: schema validation, data validation, business logic, edge cases, and performance benchmarks against an SLA. Every test ships as a runnable SQL or PySpark snippet targeting a Databricks SQL Warehouse.
The same engine that proves parity at cut-over surfaces regressions every time the downstream Delta table is rebuilt, turning a one-time migration test into permanent observability.
Test view — Eleven test cases generated automatically: schema, data, business logic, edge cases and performance.
Lineage. CT Visa generates lineage at three resolutions: intra-job (every source table, transform and target inside a single artefact), cross-job (how multiple jobs chain together across batch boundaries), and column-level (which specific source columns feed which target columns, through which join, filter or aggregate).
Every node carries an explicit type (SOURCE, MAPPING, JOIN, AGG, RESIDENT, TARGET) and every edge declares its transformation.
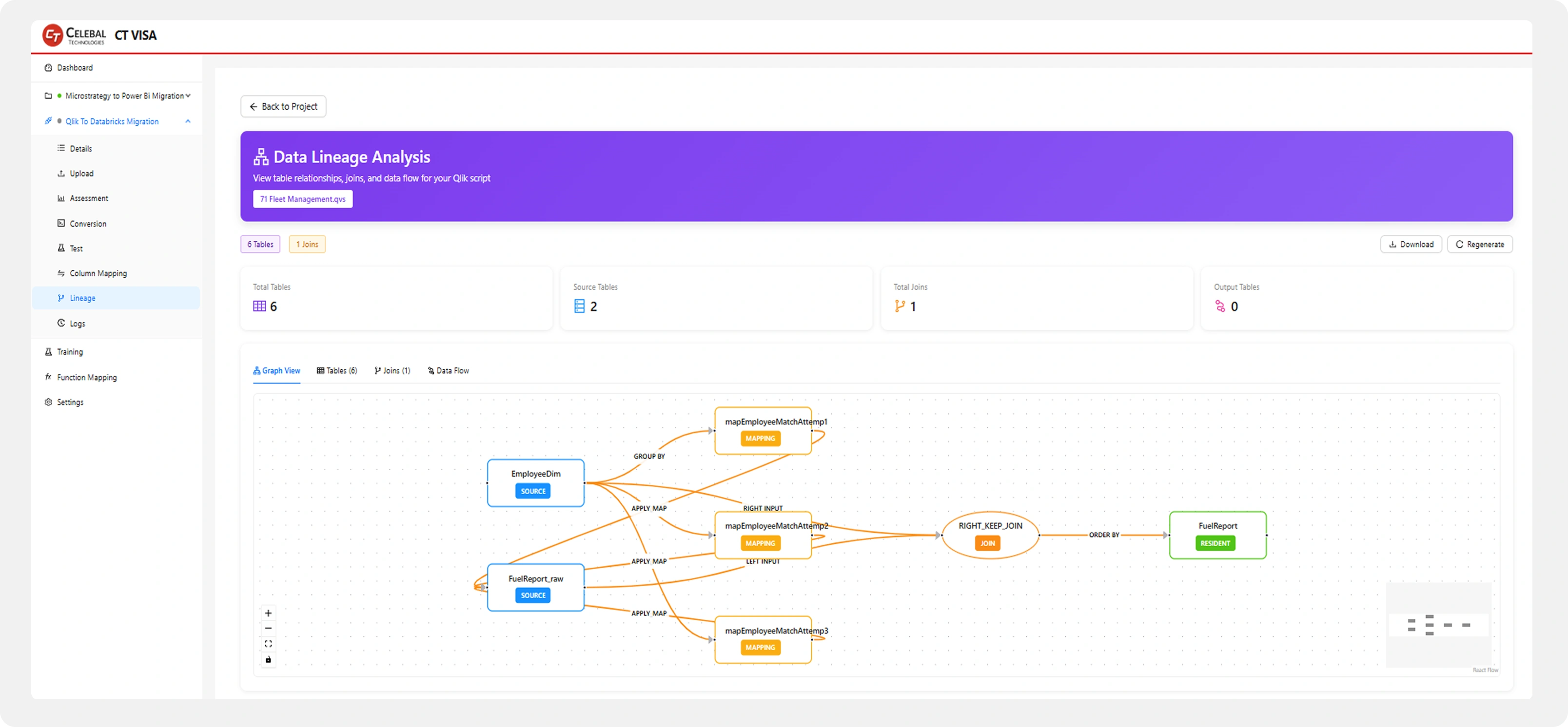
Lineage view — Interactive intra-job graph: every source table, mapping, transform and target node hand-traceable end to end.
Column Mapping. Where lineage shows the shape of the flow, Column Mapping records the fidelity. Every source column maps to its target with transformation type, expression, joining table, join type, join condition and filter captured per row: the artefact audit, data-governance and regulatory teams always request.
Qlik Apply-Map references, BODS Right-Keep joins, HANA calculated columns, Informatica unconnected lookups and Teradata correlated sub-queries are surfaced as structured columns rather than raw script a senior engineer has to decode. A live pending/mapped split tracks coverage across the project in real time.
For regulated industries, this single artefact is often the difference between a six-week audit cycle and a six-month one.
Column Mapping — Source-to-target column lineage at full fidelity: joins, filters, transformations and apply-map references captured per row.
Databricks AI Reasoning: Grounded in Engineering Truth
Every prompt is assembled deterministically from five engineered inputs: a system role framing the model as a senior Spark engineer for a specific source platform; a per-platform XML reference guide (analysis_guide.xml, conversion_guide.xml, testing_guide.xml, lineage_guide.xml) encoding unsupported features, deprecated syntax and Spark equivalents; customer-curated training examples from the Training catalog; the Function Mapping catalog of every validated source-to-target function equivalent; and the parsed object graph, never raw script text.
Output is parsed into structured JSON: complexity ratings become integers, issues become arrays, conversions become notebook bodies plus manual-change lists, lineage becomes node-and-edge graphs. Retries fall back to stricter prompts; failures surface explicitly.
The AI provider is fully pluggable: Anthropic Claude, OpenAI GPT-4o, Azure OpenAI, Google Gemini, or Databricks AI Model Servingfor enterprises that need source code in-tenant. Switching providers is one config change; the same production estate graduates from a public LLM during PoC to a customer-owned Databricks AI endpoint with zero code change.
Every prompt-template change is recorded in an XML Update History view with diff, approver and status (PROPOSED → APPROVED → APPLIED → ROLLED_BACK). Validated function mappings are woven into every subsequent conversion automatically. The platform compounds knowledge across every wave, so the program gets faster, not slower, as it scales.
CT Visa compounds migration intelligence across every wave. Validated function mappings, customer-approved transformation patterns, and curated training examples are continuously reused in future conversions, improving accuracy and reducing manual intervention as the migration program scales.
Behind the platform, CT Visa orchestrates large-scale migration workloads through a modular services architecture designed for enterprise estates running thousands of artefacts in parallel. Long-running assessments, conversions, lineage generation and validation workflows are processed asynchronously while preserving full auditability and operational traceability.
Built on the Databricks Data Intelligence Platform: Every Layer, Every Surface
Databricks Apps
Backend, frontend, and metadata store all run inside the customer's workspace. No VPC peering, no new identity provider, no extra contract. The migration platform inherits the same security posture as the workspace it lives in.
Unity Catalog Volumes
Every legacy artefact lands in a UC Volume the moment it is uploaded, governed from byte zero and audited end to end. Converted notebooks, test suites, lineage exports and column-mapping spreadsheets write back to the same governed surface. No orphan files.
Databricks AI Model Serving
Every prompt traverses the customer's own model-serving infrastructure. Source code never leaves the tenancy; LLM access falls under the same UC grants as Delta data. The regulator's "where does our code go?" question has one answer: nowhere.
Delta Lake
Every converted notebook reads and writes Delta. Incremental loads use MERGE INTO with explicit upsert keys. Performance is tuned with OPTIMIZE, Z-ORDER BY and Liquid Clustering calibrated to the source's access patterns. Three-level catalog schema-table naming throughout; time-travel preserved for audit.
Databricks Workflows
Converted notebooks deploy via the Workspace API and register as Workflows through the Jobs API. JP1 schedules become Workflow graphs, Informatica sessions become task graphs, BODS dependencies become parent-child runs. Every JobRun traces back to its originating artefact. The legacy scheduler is replaced, not paralleled.
Databricks SQL
The profiler, function-mapping discovery and test runner all execute against Databricks SQL Warehouses via the official SQL Connector. The same warehouse that powers downstream business analytics validates the migration. No new compute, no new cost line.
Lakebase Postgres
Every project, parsed object graph, complexity rating, AI prompt version, conversion result, manual-change list, lineage edge, column mapping, test result and JobRun is persisted in Lakebase Postgres, Databricks' fully managed, UC-governed OLTP store. Program leaders query migration state the same way they query Delta, and get velocity, backlog and risk answers in real time.
The Numbers That Survive a Steering Committee
- 70–85% AI conversion automation: a 4–5× leverage ratio on the most expensive talent in the program.
- 3–5× faster end-to-end delivery: parallel assess / convert / test / lineage cycles replace serial hand-coded waves. What used to be twenty-four months became seven.
- 30–60% reduction in re-platforming TCO: legacy licences retire wave-by-wave, Databricks compute scales elastically, and consultant burn-rate drops with engineer hours.
- Institutional knowledge that compounds: every wave's training examples, function mappings and prompt fragments make the next wave's AI more accurate.
Industry Case Studies: Migrations CT Visa Has the Estate For
CT Visa's supported source platforms map almost exactly onto the legacy estates Celebal has already migrated to Databricks across every industry. The anonymized record below is both proof of pattern coverage and the addressable footprint CT Visa accelerates, turning each from a multi-quarter hand-rewrite into an AI-accelerated, lineage-complete, Lakebase-audited wave.
Banking & Financial Services: Synapse, SAS, Informatica, HDInsight, SQL
Legacy warehouses and ETL inflate licence and run cost while governance breaks down, the more-efficient and CFO/Treasury use cases in the Databricks Banking map. CT Visa assesses, converts to PySpark on Delta, tests, traces lineage, and deploys, with Lakebase as the migration control plane. Celebal has migrated Synapse estates for a diversified NBFC and an NBFC lender, SAS to Databricks for a general insurer, and Informatica plus an HDInsight estate for a sovereign investment authority and a global bank, exactly the source platforms CT Visa converts.
Life Sciences: Hive, Informatica, region and application migrations
Regulated life-sciences organizations modernize toward governed clinical data repositories, the R&D-productivity use cases in the Databricks Life Sciences map. Celebal has migrated Hive to Unity Catalog for a healthcare-analytics firm, Informatica to Databricks for a healthcare-intelligence firm, and delivered application and region migrations for a health insurer and a medical-device maker, all estates CT Visa converts with lineage and validation built in.
Public Sector: Synapse and legacy ETL
Government bodies modernize toward governed platforms under audit, the optimize-operations and back-office-automation use cases in the Databricks Public Sector map. Celebal has delivered Synapse-to- Databricks for a state health department, legacy ETL migration for a government energy regulator, and migration planning for a state revenue agency. Every one of these is a real Celebal Databricks migration, and CT Visa is what compresses each into a governed, audited wave.
Media & Entertainment and Digital Natives: EMR, SageMaker, Dataiku, runtime
High-volume event platforms and SaaS scale-ups migrate from Spark-on-EMR, SageMaker ML, and third-party tooling onto the lakehouse, the identity-and-Customer360 and open-ecosystem use cases in the Databricks maps. Celebal has delivered EMR-to-Databricks for a telecom operator, SageMaker ML-to-Databricks for an online-gaming platform, Dataiku-to-Databricks for a construction-software firm, and runtime upgrades for a content-subscription platform.
Manufacturing & Energy: Teradata, Oracle, SAP BW/HANA, SSIS
Asset-heavy manufacturers and energy operators carry the largest legacy estates of all; the build-resilience and operational-dashboarding use cases in the Databricks Manufacturing map. CT Visa's SAP BW (DataSource to InfoCube to Medallion), SAP HANA Calc View, Teradata BTEQ, and Oracle PL/SQL converters target these directly. Celebal has run Teradata-to-Databricks migrations for semiconductor makers and the auto-aftermarket, SAP HANA and BW modernizations for oil & gas majors and petrochemicals, and Oracle and Synapse migrations for electronics and HVAC manufacturers.
Retail & CPG: Teradata, SAP BW, Synapse, Oracle, Redshift, BigQuery
Retailers modernize warehouse and SAP analytics estates while needing lineage preserved for governance, the customer-data-management and supply-chain-resiliency use cases in the Databricks Retail map. CT Visa converts SAP BW and warehouse estates while keeping lineage intact. Celebal has delivered Teradata-to-Databricks for a fashion-and-retail group, SAP BW-to-Databricks for luxury and cosmetics retailers, Oracle-to-Databricks with Power BI for a grocer, and Redshift and BigQuery migrations for e-commerce marketplaces.
From Legacy Scripts to Lakehouse Intelligence
The migration tool of the next decade is not a third-party SaaS that ships your legacy code to someone else's cloud. It is not a generic translator that produces PySpark you cannot debug. It is not a consulting engagement that bills you for the same engineer twice.
It is a Databricks App that runs inside your own workspace: reading source artefacts from Unity Catalog Volumes, reasoning through Databricks AI Model Serving, writing Delta Lake tables, scheduling Databricks Workflows, validating on Databricks SQL, and persisting every project, lineage edge, and run record to Lakebase Postgres, all governed end-to-end by Unity Catalog.
One Databricks platform. One control plane. One governance model. One audit trail. CT Visa does not replace your migration team. It gives every developer the first ten weeks of the program back, gives every program manager defensible numbers for steering, and gives every CFO the next ten years of licence savings to invest somewhere that actually moves the business forward.
Your legacy ETL estate is not a strategic asset. The Databricks Lakehouse is about to become one.
To explore a CT Visa proof-of-value on your own Databricks workspace, contact Celebal Technologies at enterprisesales@celebaltech.com.