Operationalizing Data & AI in
Healthcare and Life Sciences:
Migrating from Oracle Exadata to
Databricks

The Data & AI Imperative in Healthcare and Life Sciences
Healthcare and Life Sciences (HLS) enterprises manage some of the most complex data environments in the enterprise landscape. What started as systems of record for clinical transactions has grown into large, interconnected data ecosystems. These now span electronic health records (EHRs), medical imaging, real-world evidence (RWE), device telemetry, and genomics data.
This shift creates a structural mismatch between legacy data platforms and modern healthcare operating models. Systems designed for transactional processing are now expected to support intelligence production, AI enablement, and real-time clinical decisioning, functions they were never architected to perform.
Industry estimates indicate that healthcare data is growing at approximately 36% annually, driven primarily by non-traditional data types. Genomics data alone has expanded rapidly over the past decade, with public repositories now exceeding 28 petabytes. At the same time, only a small fraction of healthcare data is structured. The majority exists as free text, images, signals, and files, formats that structurally exceed the design boundaries of traditional relational database systems.
For CIOs and CDOs, this presents a fundamental challenge. Data is spread across multiple platforms and systems, yet regulatory requirements such as HIPAA, GxP, and FDA 21 CFR Part 11 demand strong controls, clear data lineage, and complete auditability. At the same time, enterprises are expected to scale analytics and AI in a responsible way, without compromising data security, regulatory compliance, or trust.
Why Oracle Exadata Becomes a Value Ceiling at HLS Scale
Oracle Exadata has long been a dependable platform for high-performance relational workloads, and many HLS enterprises continue to rely on it for core reporting and analytics. However, as data volumes increase and analytical requirements shift toward advanced modeling and AI, several structural limitations emerge.
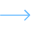
Infrastructure Scalability Limitations
Exadata scales through fixed hardware configurations, requiring capacity to be added in large increments. This model struggles to accommodate variable or burst-driven workloads such as genomics analysis, population health studies, or clinical trial simulations. The result is often over-provisioning and underutilized infrastructure.
This model introduces a structural misalignment between clinical demand variability and platform economics.
Cost and Licensing Constraints
Cost is another significant constraint. Oracle licensing is closely tied to compute cores and long-term contractual commitments. In dedicated environments, costs can rise to around $1.30 per OCPU per hour. As enterprises are required to retain data for ten years or longer to support regulatory compliance and research, expenses grow in direct proportion to data volume, rather than reflecting how frequently the data is actually used.
This economic burden is compounded by Oracle’s licensing and support structure. For example, an Oracle Exadata Exascale Database ECPU is priced at approximately $0.336 per hour, while an OCPU for dedicated infrastructure can reach $1.344 per hour. For HLS enterprises managing petabytes of historical data, this model becomes economically misaligned with long-term clinical, research, and AI objectives, particularly for storing and querying “cold” data required for long-term clinical and HEOR studies.
Limitations for Advanced Analytics and AI
Additionally, Exadata is optimized primarily for structured SQL workloads. Processing unstructured healthcare data typically requires offloading to secondary platforms, increasing data duplication and introducing governance and validation risks in regulated environments.
This fragmentation creates systemic barriers to AI operationalization in regulated environments.
Migration Overview: From Oracle Exadata to Databricks
Migrating from Oracle Exadata to Databricks represents a fundamental institutional shift, from database-centric operations to intelligence-centric platforms built on open storage and elastic compute.
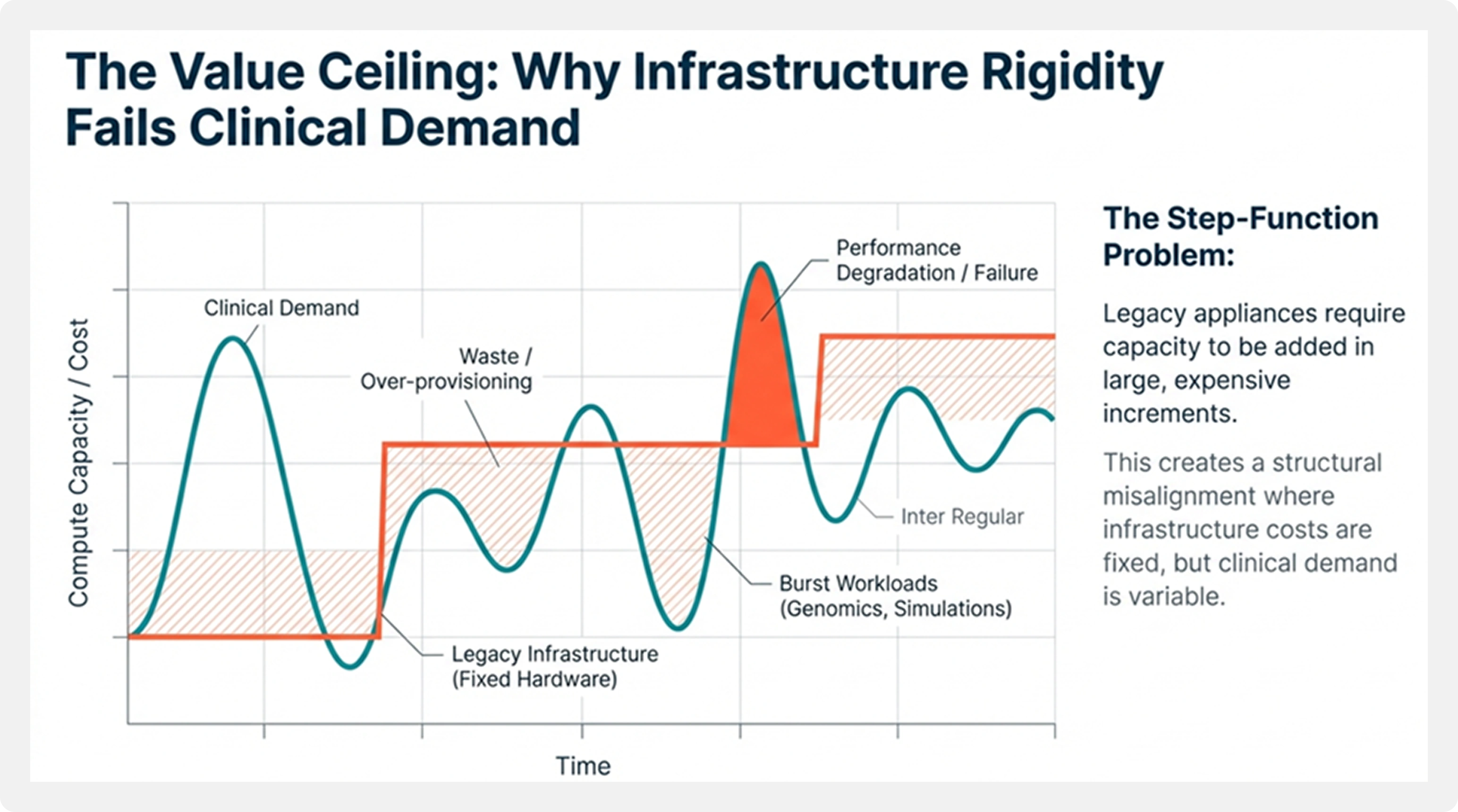
In large HLS migration programs, historical data volumes typically range from 500 TB to multiple petabytes. Daily ingestion volumes span 1 TB to over 50 TB, sourced from laboratories, connected medical devices, claims platforms, imaging systems, and external data providers. Retention periods commonly extend from 10 to 25 years to satisfy regulatory, audit, and research requirements.
By storing data in open formats such as Delta Lake on cloud object storage, enterprises dramatically reduce storage costs while keeping data continuously accessible for analytics and AI workloads.
Transitioning Retention and Ingestion Patterns
Long-Term Data Retention with Cloud Object Storage
In legacy Exadata environments, historical data retention was often constrained by physical rack capacity, forcing enterprises to archive or delete valuable clinical records. The Databricks Lakehouse, built on cloud storage platforms such as ADLS, Amazon S3, or Google Cloud Storage, enables virtually unlimited retention at a fraction of the cost.
Data transitions from a constrained operational liability to a long-term strategic asset.
Modernized Ingestion Architectures
Ingestion patterns also evolve. Rigid nightly batch ETL pipelines give way to near real-time micro-batching using Databricks Auto Loader and Lakeflow, delivering up to 12× performance improvements for the small-file ingestion patterns common in medical device telemetry and clinical data feeds.
Typical Healthcare and Life Sciences Migration Characteristics
Performance Outcomes After Migration
When analytics workloads are redesigned for distributed execution, performance gains are significant and measurable.
Performance improvements are not incremental optimizations; they reflect a change in execution model from vertical scaling to distributed intelligence processing.
Analytical queries that once took minutes or even hours to run on Exadata now typically complete 5x to 12x faster on Databricks. Overnight batch jobs that used to span several hours are often finished in under an hour. At the same time, performance remains stable as usage grows, since compute can scale independently. This allows hundreds of users to run analytical workloads in parallel without performance bottlenecks.
These performance improvements come from the Databricks Photon engine combined with the platform’s ability to scale horizontally and elastically. This flexibility becomes especially important during peak demand periods, such as regulatory reporting cycles, clinical trial analysis, and large population health studies.
Across enterprise migrations, organizations consistently report 5x to 20x faster query execution for complex analytical workloads. In healthcare and life sciences–focused implementations, some enterprises have achieved up to a 78% percent reduction in overall runtime, enabling faster delivery of clinical dashboards and pharmacy claims reports.
Performance Outcomes: Speeding Time-to-Insight
12x
Faster Analytical Queries
Inter Light
Acceleration compared to Exadata legacy benchmarks.
78%
Reduction in Runtime
Inter Light
For critical workloads like pharmacy claims reports.
< 1 Hr
Batch Processing Time
Inter Light
Reduced from overnight runs to minutes.
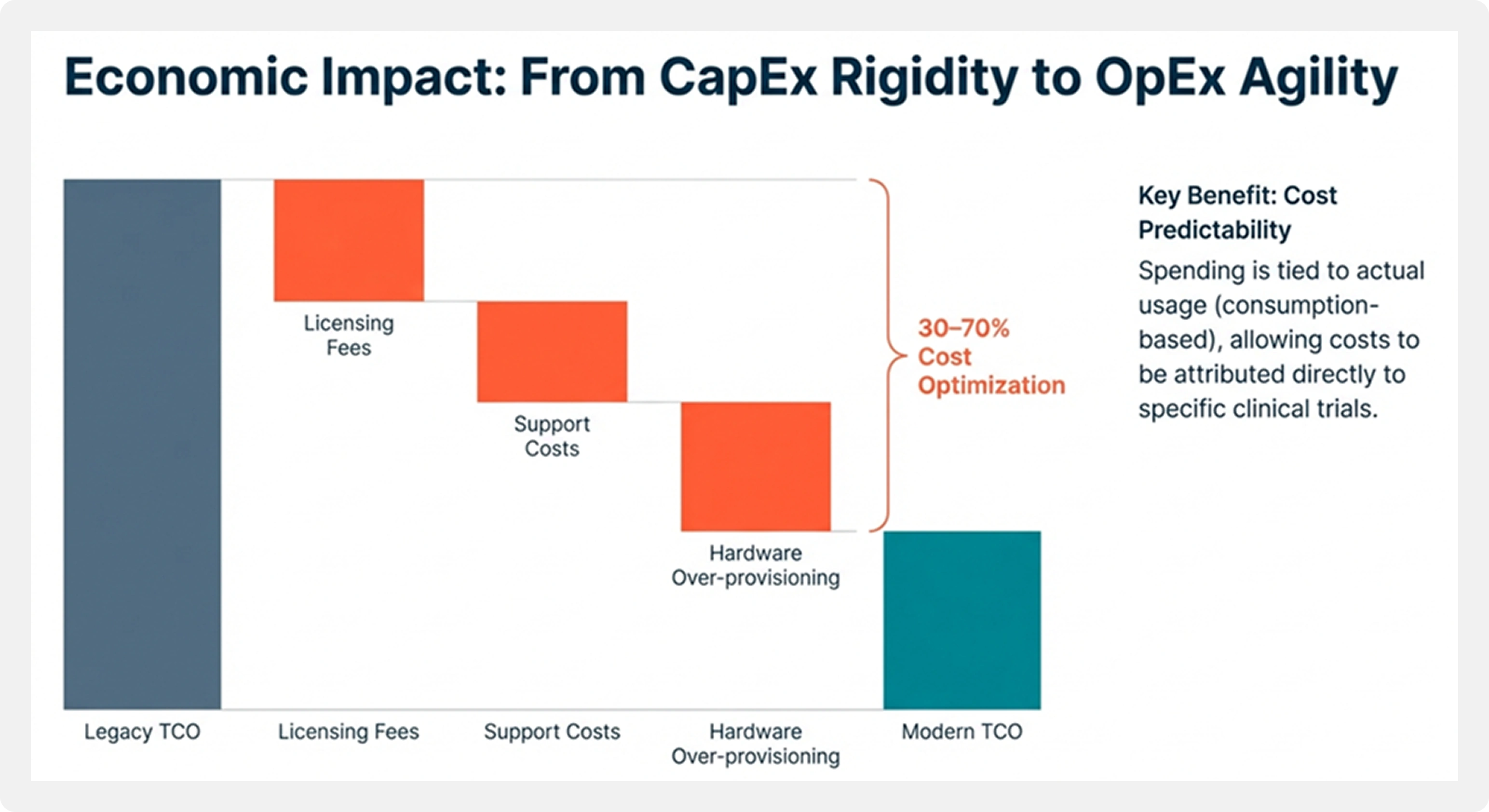
Cost and Economic Impact
The migration fundamentally changes the economic model of data—from capital-intensive infrastructure investment to consumption-aligned intelligence production.
The main economic advantage of migrating is not about fine-tuning individual components, but about shifting the overall cost model.
Exadata environments come with significant upfront capital investment, ongoing support costs, and fixed licensing commitments. Databricks, by contrast, follows a consumption-based operating expense model. Compute resources scale up or down based on demand, while storage remains low-cost and independent of compute.
In analytics-intensive healthcare and life sciences environments, enterprises typically see 30-70 percent cost optimization, depending on the mix of workloads and how deeply the platform is modernized. Cost predictability also improves, since spending is tied to actual usage rather than provisioning for peak capacity.
Migration Challenges in Regulated Healthcare and Life Sciences Environments
Migrating from a deeply entrenched platform like Oracle Exadata requires a disciplined approach. Healthcare and life sciences enterprises must address refactoring, validation, and compliance challenges while maintaining clinical safety.
PL/SQL and Stored Procedure Refactoring
The biggest technical challenge in this transition is refactoring legacy PL/SQL code. Oracle environments often include thousands of stored procedures, triggers, and packages that have built up over many years. PL/SQL follows a procedural, stateful model, whereas Spark SQL and PySpark are designed to be functional and distributed.
Automated conversion tools can usually handle 75–80 percent of the existing code. The remaining 20 percent, which often contains core clinical logic, needs to be manually redesigned to ensure both accuracy and performance at scale.
Data Reconciliation and Validation
In regulated environments, data integrity is non-negotiable. Reconciling petabytes of data requires sophisticated validation strategies, including:

Speed vs. Accuracy
Stochastic check summing and sampling to validate data at scale

Schema Evolution
Careful mapping between Oracle NUMBER and Spark DECIMAL to prevent rounding errors

Validation Tooling
AI-assisted approaches for cell-level verification of clinical attributes
Governance Transformation and Change Management
The transition from centralized, DBA-driven governance to modern data governance models requires both technical and cultural change. Identity systems such as Azure AD and Okta must be integrated at scale, and users must be trained to work efficiently in distributed environments to avoid cost and performance pitfalls. This transition represents not only a technical shift, but a governance operating model transformation.
Reference Architecture Patterns for Healthcare and Life Sciences
Successful migrations rely on repeatable architectural patterns rather than one-off implementations.
Workloads are categorized into those to be retained, migrated, or fully modernized. Data is organized into layered architectures that preserve raw data while enabling standardized clinical models such as FHIR and OMOP. Governance controls are enforced from ingestion onward, ensuring consistent access control, lineage, and auditability. Feature pipelines are centralized so AI models consume trusted, validated data.
These patterns reduce delivery risk while enabling long-term scalability and regulatory compliance.
Business and Technical Outcomes
Migrating from Oracle Exadata to the Databricks Lakehouse delivers outcomes that directly align platform modernization with healthcare and life sciences objectives.
Faster Time-to-Insight and Higher Reliability
Enterprises typically experience up to 80% faster time-to-value for new data initiatives. Analysts can build clinical dashboards in weeks instead of months, while managed cloud infrastructure delivers significant reductions in platform downtime.
Regulatory Confidence and Cost Predictability
Modern governance and lineage capabilities enable end-to-end auditing, reducing compliance reporting effort by up to 40%. The consumption-based cost model provides transparency into compute usage per clinical trial or research program, aligning spend with business value.
Enterprise AI Industrialization Capability
By unifying structured data with most healthcare data that is unstructured, enterprises establish an AI-ready foundation. This enables advanced use cases such as biomedical literature analysis, clinical decision support, and automated clinical documentation.
Conclusion: Preparing for the Next Decade of Healthcare Data
Healthcare and life sciences enterprises face increasing pressure to scale data and AI without compromising regulatory obligations. Platforms designed for a previous era struggle to meet today’s data diversity and analytical demands.
Migrating analytical workloads from Oracle Exadata to Databricks provides a scalable, compliant foundation for modern healthcare analytics. In this context, platform strategy becomes enterprise strategy. This approach enables enterprises to move beyond siloed systems and build data platforms designed for long-term innovation and clinical impact.