The Database Decision That
Shaped CT Vision’s Operational
Architecture

Why we stopped treating the operational database as an afterthought, and what we built instead
Enterprise AI platforms are not usually blocked by model quality. They are blocked by the infrastructure surrounding the model, the credential management, the network boundaries, the compliance reviews, and the operational fragmentation that accumulates when AI compute lives in one environment and operational state lives somewhere else entirely.
That was the problem we needed to solve for CT Vision.
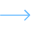
CT Vision is an enterprise-grade AI video analytics platform built natively on Databricks. It enables enterprises to upload, process, and extract structured intelligence from video footage at scale. When we designed the operational architecture, we made a deliberate choice: keep everything, users, video processing jobs, KPI extraction results, annotation records, ML training lifecycles, inside the Databricks workspace boundary, using Databricks Lakebase as the operational database.
This blog explains why we made that choice, what it looks like in practice, and what it means for the enterprises deploying CT Vision.
Why Enterprise Video Intelligence Is Harder Than It Looks
Large enterprises are sitting on vast libraries of unstructured video footage: retail floor recordings, industrial inspection feeds, traffic monitoring, and field operations. The challenge is no longer capturing video. It is extracting consistent, auditable, and actionable intelligence from that footage at scale, in a way that meets enterprise compliance requirements.
Enterprises that attempt to build these pipelines internally run into three compounding problems:
Fragmented infrastructure
AI compute, storage, and operational databases live in different environments with different security perimeters, different credential lifecycles, and different governance models. Every additional system is another thing to provision, monitor, and secure.
Schema brittleness
AI models evolve continuously. KPI definitions change. Confidence scoring methodologies mature. Every model update risks breaking the data schema and triggering migration work before insights can resume.
Compliance friction
Enterprise contracts increasingly require data residency guarantees and end-to-end auditability. A pipeline that spans multiple cloud services and network boundaries makes those guarantees difficult to provide, and even harder to prove.
"The question was never whether we could extract insights from video. It was whether we could do it in a way that an enterprise security team would sign off on, and that an operations team could actually run."
Why the "Just Use RDS" Answer Didn't Work for Us
When we started designing CT Vision on Databricks, the first question we had to answer was: where does operational state live?
The default industry answer is an external managed database such as RDS, Cloud SQL, Azure Database for PostgreSQL. For most applications, that is a perfectly reasonable choice. For CT Vision, it created a structural contradiction.
CT Vision is built entirely inside the Databricks workspace:
- Unity Catalog for governed storage
- Model Serving for AI inference
- Vector Search for semantic retrieval
- Jobs API for ML training workflows
Routing operational state through an external database would punch a hole through that boundary. Specifically, it would introduce:
- A separate network boundary requiring VPC peering or private link configuration
- A separate credential lifecycle, connection strings stored as secrets, rotated on their own schedule
- Cross-network latency on every transactional read and write
- A second governance perimeter that Unity Catalog cannot see into
- Infrastructure provisioning work that blocks every new customer deployment
For a platform where data residency and auditability are contractual requirements, this was architecturally unacceptable. The AI system needed to be secure end-to-end, not secure everywhere except the operational database.
The Schema Evolution Problem
There is a second, less obvious challenge specific to AI platforms: output schema instability.
When a language model extracts KPIs from video, the structure of that output changes over time as prompts improve, as new KPI types are added, and as confidence scoring methods evolve.
A normalized relational schema cannot absorb these changes without migration scripts. In a production environment serving multiple enterprise clients, migration scripts are operational risk events, coordinated releases with real downtime implications.
We needed a schema strategy that could keep pace with the AI layer without creating friction every time a model improved.
What Changes When the Database Is Inside the Workspace
Databricks Lakebase is a fully managed Postgres service that runs inside the Databricks workspace boundary. It is not a data warehouse. It is not an analytics layer. It is a fully transactional operational database, purpose-built for applications that need fast structured reads and writes, and that already live inside Databricks.
For CT Vision, this means every piece of operational state lives in a Lakebase instance that is co-resident with the compute, storage, and AI services the platform depends on. CT Vision composes its database connection from Databricks-provided Postgres environment variables at runtime. No external operational database is required.
The Structural Shift, Made Concrete
Lakebase eliminates the structural contradiction of the external database. Because it sits inside the workspace boundary:
Minimal network configuration by default
In the standard deployment path, there is no VPC peering, no private link setup, and no firewall rules to configure. The database is reachable from application compute the same way Unity Catalog storage is reachable. Enterprise teams that require additional private connectivity can still apply PrivateLink, IP allowlists, or network policies at the workspace layer.
No external database credential lifecycle
CT Vision composes its Postgres connection from Databricks-provided environment variables at runtime. There is no external database password to store or rotate. Authentication uses Databricks OAuth with managed token refresh, so the credential lifecycle stays within the Databricks-native model.
No second governance perimeter
Security controls are Unity Catalog permissions and OAuth authentication, the same controls that govern the rest of the platform.
No infrastructure to provision per deployment
A new customer environment is a Databricks Apps deploy command. The database bootstraps itself.
Inside the Schema: Twelve Tables, One Boundary
CT Vision's Lakebase instance carries twelve operational tables, organized around the platform's core workflows:
Identity & Access
• users: Application identity, role (Admin / User / Viewer), bcrypt-hashed credentials. No external identity provider dependency in the base deployment.
Video Processing Pipeline
• bundles: Logical groupings of videos with JSONB KPI definitions. A kpi_version integer column enables staleness detection: a single comparison flags whether a video's analysis is current against the latest KPI set.
• videos: Upload metadata, UC Volume path, processing status (UPLOADING → PROCESSING → COMPLETED / FAILED), and uploader reference.
• processed_videos: AI pipeline output: summary text, structured events (JSONB array), KPI results (JSONB map of name → value + confidence + frame samples). JSONB absorbs prompt evolution without schema changes.
• notifications: Per-user processing events, progress percentages, read flags. Polled over REST, no message broker required.
ML Training Lifecycle
• training_jobs: Full lifecycle tracking: Databricks run ID, state machine (QUEUED → RUNNING → COMPLETED / FAILED / CANCELLED), training configuration as JSONB, per-epoch metrics as JSONB array, full transition history. Every state change is auditable.
Annotation Studio
• datasets, dataset_images, annotations: Annotation shapes stored as JSONB arrays (bounding boxes, polygons), linked to images in UC Volumes.
• model_projects, rate_limits: Project groupings and per-user rate limit windows.
The Column Type That Lets AI Models Evolve Without Breaking the Database
The decision to store AI output in JSONB columns rather than normalized relational tables is one of the most consequential design choices in CT Vision's schema, and worth explaining carefully.
A bundle may define five KPIs today and eight next month. Each KPI has a name, a numeric or boolean value, a confidence score, and a per-frame sample array. Normalizing this into a kpi_values table would require a schema migration every time a client changes their KPI definitions. In a multi-tenant production environment, that is a coordinated release event with real operational risk.
With JSONB, the KPI structure is owned by the application layer. Clients add KPIs; the database absorbs the change without a migration. Crucially, this flexibility does not come at the cost of queryability.
PostgreSQL's JSONB indexing and path extraction operators mean CT Vision can query KPI results by key, filter events by type, and aggregate training metrics by epoch, all against JSONB columns, all through SQLAlchemy's parameterised query interface.
With the right JSONB indexes and query design, CT Vision gets schema flexibility without forcing migrations. PostgreSQL makes both possible simultaneously.
What "Deploy in Seconds" Actually Means
CT Vision's startup sequence shows what a workspace-native architecture looks like in practice. Every new environment bootstraps itself without manual intervention:
- Uvicorn starts on DATABRICKS_APP_PORT
- FastAPI lifespan initialises the SQLAlchemy engine, pointed at DATABASE_URL
- create_all() bootstraps any missing tables on first run, no manual schema setup required
- OAuth M2M token is fetched and cached
- StorageProvider, SearchProvider, and VisionProcessor initialise
- Background workers start and the application becomes ready
The Lakebase connection is a hard dependency at step two. If it fails, nothing else starts. This is intentional; the operational state is not optional. Because Lakebase is inside the workspace, the connection either works or it does not. There is no firewall rule to check, no peering connection to validate, no cross-region latency to troubleshoot.
What Enterprise Teams Actually Get
For Enterprise Buyers
The three concerns that most often slow or block enterprise AI procurement are data residency, auditability, and security posture. The Lakebase architecture addresses all three directly.
Data residency.
All operational state, including user data, video metadata, extracted intelligence, and training histories, stays within the Databricks workspace. There is no external database endpoint to scope into a data processing agreement.
Auditability
Every video processing event, KPI extraction, training job transition, and user notification is a PostgreSQL row with timestamps and foreign keys. The audit trail is complete, queryable, and in the same database as the application data.
Security posture
One workspace, one security perimeter, one credential model. No external endpoints to scope into penetration testing or SOC 2 audits.
For Platform Operations Teams
Deployment speed
New environments deploy with a single command. No database infrastructure to provision, no VPC to configure, no firewall rules to open.
Operational simplicity
No external database to monitor, patch, or scale independently. Lakebase is managed infrastructure within the workspace.
Schema agility
As AI models improve and KPI definitions evolve, JSONB storage absorbs those changes at the application layer, significantly reducing migration pressure for AI output fields.
The Architecture Compared
| Challenge | Traditional Approach | With Lakebase |
|---|---|---|
| Database deployment | VPC peering + firewall rules | Zero network configuration |
| Credential management | Secrets manager + rotation policy | Single DATABASE_URL at runtime |
| AI schema evolution | Migration scripts per release | JSONB reduces migration pressure for AI output fields |
| New environment setup | Hours of infrastructure provisioning | Fast startup via create_all() bootstrap |
| Audit & governance | Fragmented logging infrastructure | Timestamps + FK trail in the same DB |
Industry Case Studies: Where CT Vision Creates Value
CT Vision is industry-agnostic at the platform layer and industry-specific at the agent layer. The same Lakebase-backed, Unity Catalog-governed architecture powers very different vision problems depending on the sector; only the agent pool changes. Here is where it lands, and the Celebal Databricks footprint that backs each.

Energy & Utilities: Asset inspection and grid reliability
Transmission and distribution operators inspect transformers, substations, and feeders that are geographically dispersed, safety-critical, and historically inspected by eye. Manual inspection is slow, subjective, and leaves blind spots, exactly the Industrial AI and critical-infrastructure monitoring problem Databricks frames for the sector.
CT Vision automates transformer and asset inspection: it detects rust, oil leaks, vegetation encroachment, and structural damage, applies a standardized A–E severity grade, auto-completes inspection forms, and pushes them to the system of record.
Celebal has already delivered automated transformer inspection and work-order automation for a North American electricity utility, and its wider energy-and-utilities Databricks footprint spans integrated oil & gas majors, national oil companies, power generators, and water-and-electricity utilities.

Manufacturing: Defect detection and quality forensics
On high-throughput lines, defects and safety events are caught late; quality assessment is inconsistent across shifts, and video and sensor data sits unused.
CT Vision's vision agents run defect detection, production monitoring, and quality-event forensics against live camera and sensor feeds, mapping to Databricks' Manufacturing Industrial AI use cases, and turn raw video into structured, searchable evidence.
Celebal has delivered computer-vision and industrial-AI engagements in manufacturing, including automated-guided vehicle vision automation at a bottled-beverage manufacturer and anomaly detection for a power-grid technology maker.

Public Sector & Transportation: Critical-infrastructure monitoring
Agencies and grid operators must monitor critical infrastructure and public spaces continuously but cannot staff a human on every feed.
CT Vision provides automated monitoring, blind-spot and anomaly detection, and intelligent alerting across infrastructure and transportation video, mapped to the Databricks Public Sector use cases for critical-infrastructure monitoring, predictive maintenance, and smart transportation.
Celebal's public-sector Databricks footprint includes grid operators and government giga-project authorities whose mandate is exactly this kind of monitoring.

Retail: Store, safety, and operations intelligence
Retailers capture floor and back-of-house footage but rarely convert it into operational insight on safety, compliance, or process.
CT Vision turns store and distribution-center video into operational intelligence, safety and compliance monitoring, process adherence, and incident detection, feeding the same governed customer-and-operations estate retailers already run on Databricks.
Celebal operates large governed Databricks estates for grocery, fashion, and sportswear retailers, where the customer-data backbone CT Vision's operational insights extend.

Life Sciences & Healthcare: Inspection and imaging
Regulated manufacturing and clinical environments demand consistent visual inspection and auditable evidence.
CT Vision applies the same governed inspection pipeline to GxP manufacturing lines and image-classification workflows, with Unity Catalog lineage from frame to finding.
Celebal's life-sciences Databricks footprint spans global pharma, medical-device, and healthcare-provider organizations operating under strict audit requirements, where consistency and traceability are the whole point.
Across all five sectors the platform is identical: agentic vision on Databricks, Lakebase as the operational record, and Unity Catalog governing every frame and every finding. Only the agent pool changes.
Governance Isn't a Feature. It's the Architecture
The deepest principle behind CT Vision's use of Lakebase is not technical, it is organizational.
Enterprise AI platforms are judged not only on the quality of their insights, but on the credibility of their governance. A platform that punches holes in its own security boundary for database access has a governance story that is genuinely harder to tell, harder to document, harder to audit, and harder to sell.
Lakebase closes that gap. With compute, storage, AI inference, vector search, model training, and operational state all inside a single Databricks workspace, CT Vision can make a claim that matters to enterprise buyers: your data does not leave the perimeter.
For platform teams evaluating CT Vision: there is no database infrastructure to provision, configure, or secure outside Databricks. The platform is the workspace.
One workspace. One deployment boundary. Zero external infrastructure.
Interested in how CT Vision can work for your enterprise? Reach out at
enterprisesales@celebaltech.com