Building a Robust SFTP to Lakehouse ETL
Pipeline with Microsoft Fabric:
A Complete Guide


In today's data-driven landscape, organizations frequently need to ingest data from various external sources, with SFTP (Secure File Transfer Protocol) being one of the most common methods for secure file transfers. While traditional ETL tools can handle SFTP ingestion, Microsoft Fabric offers a unified platform that
streamlines the entire process from data ingestion to analytics-ready insights.
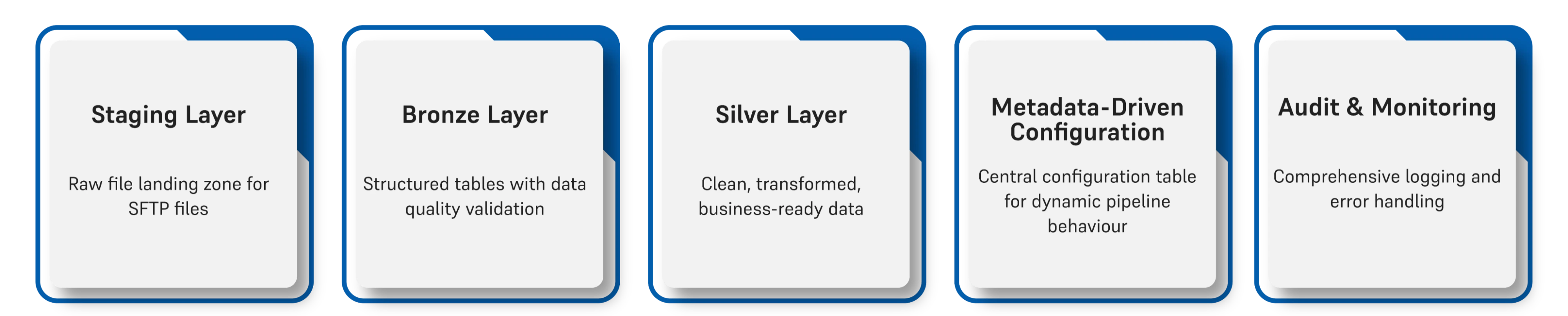
In this comprehensive guide, I'll walk you through building a production-ready, metadata-driven ETL pipeline that ingests CSV files from an SFTP source and processes them through Microsoft Fabric's Lakehouse architecture using the medallion pattern (Staging → Bronze → Silver).
Why Choose Microsoft Fabric for SFTP ETL?
Microsoft Fabric provides several advantages for SFTP data ingestion:
Unified Platform
Single platform for data engineering, data science, and analytics
Medallion Architecture Support
Native support for Bronze, Silver, Gold data layers
Metadata-Driven Approach
Configuration-based pipeline execution
Built-in Monitoring
Comprehensive logging and alerting capabilities
Cost-Effective
Pay-per-use model with automatic scaling
Architecture Overview
Our solution follows the medallion architecture pattern:
Prerequisites
Before we begin, ensure you have:
- Microsoft Fabric workspace with Data Engineering license
- SFTP server credentials and access paths
- Permissions to create pipelines, notebooks, and Lakehouse tables
- On-premises data gateway (if SFTP server is on-premises)
Step-by-Step Implementation
1. Setting Up the Foundation
Create Workspaces and Lakehouses
1. Create Workspaces
2. Create Lakehouses
3. Create Data Warehouse
Configure SFTP Connectivity
If your SFTP server is on-premises:
- 1.Download and install the On-premises data gateway
- 2.Register the gateway with your Fabric account
- 3.Add SFTP data source in Fabric Admin portal with connection details
2. Metadata Infrastructure Setup
Create Essential Database Objects
1. SOURCE_METADATA_CONFIG Table
CREATE TABLE [dbo].[SOURCE_METADATA_CONFIG] ( [SOURCE_TYPE] VARCHAR(50), [LAYER] VARCHAR(20), [SOURCE_SERVER] VARCHAR(100), [SOURCE_DATABASE] VARCHAR(100), [SOURCE_TABLE] VARCHAR(100), [PRIMARY_KEY] VARCHAR(500), [NON_KEY_COLUMNS] VARCHAR(MAX), [BRONZE_TABLE_NAME] VARCHAR(100), [SILVER_TABLE_NAME] VARCHAR(100), [SCD_FLAG] INT, [ACTIVE_FLAG] INT );
2. Audit Tables
3. Stored Procedures
Configuration: Manages audit logging
3. Building the Core Pipeline
Master Pipeline: Data_Ingestion_SFTP_Pipeline
The master pipeline orchestrates the entire flow:
_CONFIG for staging layer files
Child Pipeline: Data_IngestionSFTP-Child
This pipeline handles individual file processing:
Key Activities
Error Handling Flow
- •Success: Updates audit log with success status
- •Failure: Logs error details and triggers alerts
4. Data Quality and Transformation
Bronze Layer Processing
The Bronze layer notebook (staging_to_bronze) implements sophisticated data quality checks:
Key Functions:
- •Removes completely null rows
- •Filters null primary key records
- •Handles duplicate detection
- •Returns clean and rejected dataframes
• File reading with format detection
• Column name standardization
• Data quality validation
• SCD Type 1/2 logic implementation
• Error record logging
• Audit trail maintenance
Advanced Features:
- •Dynamic Schema Handling: Automatically adapts to varying file structures
- •SCD Support: Configurable Slowly Changing Dimension logic
- •Composite Key Generation: Creates business keys from multiple columns
- •Partition Management: Implements date-based partitioning
- •Error Isolation: Separates invalid records for investigation
Silver Layer Transformation
The Silver layer pipeline (Silver_Layer_Transformation) focuses on:
1. Metadata-Driven Processing
Reads Bronze-to-Silver configuration
2. Business Rules Application
Implements data transformations
3. Data Standardization
Reads Bronze-to-Silver configuration
4. Performance Optimization
Uses Delta Lake features for efficiency
5. Monitoring and Alerting
Comprehensive Audit Trail
Pipeline-Level Monitoring
Data Quality Monitoring
Business Monitoring
Alert Mechanism
Automated email alerts are triggered for:
Best Practices and Optimization Tips
Performance Optimization
1. File Partitioning: Autonomously prescribes and schedules repairs, orders replacement parts, and adjusts production lines to avoid downtime
2. Delta Lake Optimization: Use Z-ordering and auto-compaction
3. Parallel Processing: Leverage Fabric's auto-scaling capabilities
4. Caching Strategy: Cache frequently accessed metadata
Error Handling
1. Graceful Degradation: Continue processing other files on individual failures
2. Retry Logic: Implement exponential backoff for transient failures
3. Dead Letter Processing: Route failed records for manual investigation
4. Monitoring Integration: Connect with existing monitoring systems
Security Considerations
1. Credential Management: Use Azure Key Vault for sensitive information
2. Network Security: Implement proper firewall rules for SFTP access
3. Data Encryption: Ensure end-to-end encryption for sensitive data
4. Access Control: Implement role-based access to Fabric resources
Real-World Scenarios and Use Cases
→Scenario 1: Daily Batch Processing
- Process daily CSV exports from ERP systems
- Handle late-arriving files with configurable time windows
- Implement business day calendar awareness
→Scenario 2: High-Frequency Data Ingestion
- Process files every few minutes
- Implement micro-batch processing patterns
- Handle schema evolution gracefully
→Scenario 3: Multi-Tenant Architecture
- Support multiple SFTP sources
- Implement tenant-specific processing rules
- Maintain data isolation and security
Troubleshooting Common Issues
Connection Issues
- Problem: SFTP connection timeouts
- Solution: Verify gateway connectivity, check firewall rules, implement retry logic
Data Quality Issues
- Problem: Unexpected data formats
- Solution: Enhance validation rules, implement schema evolution handling
Performance Issues
- Problem: Slow processing for large files
- Solution: Implement file splitting, optimize Spark configurations, use Delta Lake features
Extending the Solution
Create Workspaces and Lakehouses
Adding New File Formats
The architecture supports easy extension for different file formats:
- Modify the process_data() function to handle JSON, XML, or Parquet files
- Update metadata configuration to specify file format
- Implement format-specific validation rules
Implementing Near Real-Time Processing
Transform the batch pipeline to near real-time:
- Use Fabric Event Streams for file arrival detection
- Implement micro-batch processing with shorter intervals
- Add streaming analytics capabilities
Advanced Analytics Integration
Extend the Silver layer for advanced analytics:
- Add Data Science workspace integration
- Implement ML feature engineering
- Connect to Power BI for real-time dashboards
Conclusion
Building a robust SFTP to Lakehouse ETL pipeline with Microsoft Fabric provides organizations with a scalable, maintainable, and cost-effective solution for data ingestion. The metadata-driven approach ensures flexibility, while the medallion architecture provides clear data quality progression from raw to analytics-ready data.
The solution we’ve built offers:
→Scalability: Handles growing data volumes automatically
→Reliability: Comprehensive error handling and retry mechanisms
→Maintainability: Configuration-driven approach reduces code maintenance
→Observability: Detailed logging and monitoring capabilities
→Security: Built-in security features of Microsoft Fabric
As organizations continue to embrace cloud-native analytics platforms, Microsoft Fabric's unified approach to data engineering, data science, and analytics makes it an ideal choice for modern ETL workloads.
Next Steps
To implement this solution in your environment:
Start Small
Begin with a single file type and gradually expand
Test Thoroughly
Validate with sample data before production deployment
Monitor Closely
Implement comprehensive monitoring from day one
Document Everything
Maintain clear documentation for future maintenance
Plan for Growth
Design with scalability in mind
Have you implemented similar SFTP ETL solutions with Microsoft Fabric? Share your experiences and challenges in the comments below!