How Combining Databricks Fine-Tuning and RAG is a Game Changer
BY CELEBALTECH BLOGS 2024-06-17 20 MINS READ
BY CELEBALTECH BLOGS
2024-06-17
20 MINS READ
Key Takeaways
- 1. Transition from RAG to LLM Fine-Tuning
- 2. Customization of LLMs for Specific Business Needs
- 3. Benefits of Fine-Tuning LLMs
- 4. Practical Guide to Using Databricks Foundational Model Training API
In today's competitive business environment, delivering exceptional customer experiences is essential. Unfortunately, long hold times, generic responses, and a lack of personalization can undermine customer satisfaction. To address these challenges, we've embarked on a journey to enhance our customer support systems using advanced language models.
Our Journey with Retrieval-Augmented Generation (RAG)
Initially, we utilized Retrieval-Augmented Generation (RAG) to improve the accuracy of customer interactions. RAG works by fetching relevant information from a vast repository of documents to generate responses. However, despite its promising capabilities, RAG often produced irrelevant answers, included unnecessary verbiage, and struggled with understanding domain-specific terminologies. These limitations prompted us to seek a more robust solution.
Transitioning to Fine-Tuned Large Language Models on Databricks
To overcome the shortcomings of RAG, we shifted our focus to fine-tuning Large Language Models (LLMs) on Databricks. This approach allows us to tailor the LLMs to our specific business needs, ensuring that the generated responses are not only accurate but also highly relevant to our customers. Fine-tuning LLMs enables us to address the unique challenges of the banking sector, offering a level of customization that generic models cannot achieve.
The Fine-Tuning Process and Its Benefits
The process of fine-tuning involves calibrating the LLMs to better understand and respond to domain-specific contexts and vocabulary, thereby significantly reducing the occurrence of irrelevant responses or “hallucinations.” By fine-tuning these models, we’ve been able to maintain a consistent and specific style in our responses, leading to enhanced accuracy and relevance of the information delivered to customers.
Practical Guide to Using Databricks Foundational Model Training API
In addition to its informative content, our blog serves as practical guide for utilizing the Databricks Foundational Model Training API , renowned for its user-friendliness and ease of use. By the end of this blog, readers will gain a comprehensive understanding of how to leverage this technology to fine-tune LLMs effectively, not just within the banking sector but across various industries.
Let’s get started!
To give our readers a clear path through our experiences and insights, the blog is structured into three main sections:
| Discussing our initial approach and the lessons learned from using RAG. | |
| Exploring the detailed process of fine-tuning LLMs and the benefits over generic models. | |
| A look at how integrating both technologies enhances the effectiveness of our solutions. |
By sharing our journey and the detailed process of enhancing LLMs, we hope to empower the readers to revolutionize their domain specific RAG systems through the power of fine-tuned language models.
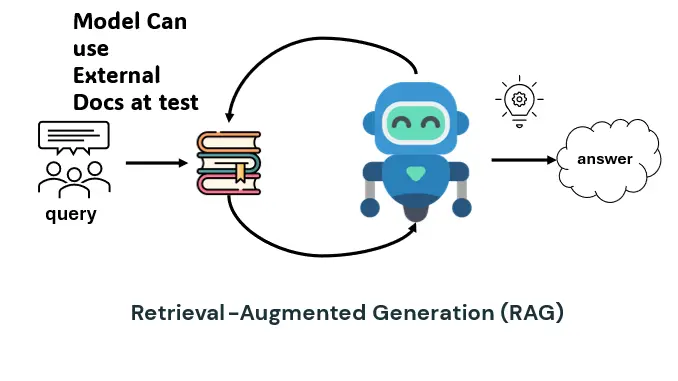
Section 1: Retrieval-Augmented Generation (RAG)
In our effort to enhance the customer experience, we initially implemented Retrieval-Augmented Generation (RAG) to improve the accuracy and relevance of responses provided by our customer support systems. This approach uses an external knowledge base, drawing on a wealth of specialized information to address the limitations of pre-trained language models.
What is Retrieval-Augmented Generation (RAG)?
RAG is a method where a language model checks an external knowledge base for information before answering questions.
Sample Data:
Here is some sample data for building a RAG system:
"Question": "What are the benefits of a cash deposit machine?"
"Example knowledge base content": "Information from bank websites, product description, previous chat content, etc."
Achieved Results:
Provided accurate and relevant answers based on the latest information from the external knowledge base.
Below are examples of the results we have obtained:
Question: "If I am changing my phone what is the right thing to do with my Google Pay?"
RAG Answer: "To mitigate the risk of security breaches and ensure a seamless transition, if you change your mobile device, you need to re-tokenize your payment cards and
change your default Tap & Pay card for contactless payments. To use Google Pay on your new phone, you must tokenize your cards again, ensuring a seamless transition and continued usage of the service.
You can also remove your ABC Bank cards from Google Pay and log out to ensure the security of your accounts. Additionally, you can call
your card issuer to de-register your card on a per-use case basis if necessary. Google Pay is a digital wallet platform designed for making in-app and tap-to-pay
purchases on mobile devices using either cards or UPI platforms."
Ground Truth: "You can delete all your cards one at a time in Google Pay. You should also log out of the Google Pay app and uninstall the app."
Observation: "You can see that the RAG provided an answer, but it contained a lot of extra information. Also, the style of the answer is not in line with the provided data."
What can go wrong with RAG applications?
While RAG significantly improved performance, several challenges were identified:
- Large prompts requiring extensive experimentation
- Difficulty understanding niche terminology and linguistic nuances
- Knowledge cut-off
- Use of larger models to get better results
- Lack of prior understanding of specific data
- Irrelevant retrieval and generation
Pretrained LLMs are broadly trained, making them generally knowledgeable but not specialists within specific domains. This can result in inaccurate data, which may lack precision in certain specialized fields. Consequently, we observed an answer correctness of only 51%, as measured by the Ragas score. For more detailed evaluation metrics, refer to Table 1: Evaluation Metric.
Section 2: LLM Fine-Tuning (FT) using Databricks Foundation Model Training API
To overcome the problems encountered with RAG, we fine-tuned a pre-trained LLM to our specific domain, expecting it to provide accurate and domain-relevant responses.
LLM Fine-Tuning
The initial step was to start the LLM fine-tuning using our domain-specific data (customer support FAQ data in our case). This step was critical for ensuring that the model could correctly interpret and respond to domain-specific queries. We used a dataset of 50,000 examples which contained questions and their respective answers.
Databricks Foundation Model Fine-Tuning API supports three kinds of fine-tuning:
- Instruction Fine-Tuning: Use this to fine-tune your model on prompt-response data.
- Chat Completion: Use this to fine-tune your model on multi-turn chat data.
- Continued Pretraining: Use this task to continue training your model with additional text data.
Supervised Fine-Tuning / Instruction Fine-Tuning
We created prompts and answers to train the model to accurately follow directions. This method uses pairs of prompts and responses to train the model to exhibit the desired behaviors for various types of inquiries. Use this to adapt your model to a new task, change its response style, or add instruction-following capabilities.
Here is an example of the training data used for instruction fine-tuning; the data just contains the prompt and responses. Training data needs to be stored in Unity Catalog.
[
{
"prompt": "How can I reset my online banking password?",
"response": "To reset your online banking password, go to the login page and
click on 'Forgot Password'. Follow the instructions to reset your password
using your registered email or phone number."
},
{
"prompt": "What are the working hours of your customer service?",
"response": "Our customer service is available from 9 AM to 5 PM, Monday through Friday."
}
]
Chat Completion
This method trains the model how to behave as a conversational user or assistant. To simulate information interactions characteristic of specific domain, like banking, we create a series of user-assistant dialogues.
Here is an example of the training data format used for chat completion:
[
{
"role": "system",
"content": "You are a banking chatbot answering user queries."
},
{
"role": "user",
"content": "How can I reset my online banking password?"
},
{
"role": "assistant",
"content": "To reset your online banking password, go to the login page and
click on 'Forgot Password'. Follow the instructions to reset your password
using your registered email or phone number."
},
{
"role": "user",
"content": "Are pensioners required to set up a specific account in a recognized
bank to receive their pension funds?"
},
{
"role": "assistant",
"content": "The pensioner is not required to open a separate Pension Account.
The pension can be credited to his or her existing Savings Account maintained
with any branch of the bank selected by the pensioner."
}
]
Continued Pre-Training
Similar to other pre-training tasks, the training data is your original unstructured text data. In developing the training data, the following are deemed relevant: text files where each file’s content is considered as one sample for processing.
Here is how training data is structured for continued Pre-Training; in this task, data does not need to be labeled. Training data can just be large chunks of texts. Training data is not required to be in a specified format; .txt files containing texts need to be stored in Unity Catalog:
banking_policy_document.txt # The entire content of banking_policy_document.txt is considered as one sample
financial_statement_2023.txt # The entire content of financial_statement_2023.txt is considered as one sample
customer_service_transcripts.txt # The entire content of customer_service_transcripts.txt is considered as one sample
We fine-tuned mistralai/Mistral-7B-v0.1 on our data. We chose the Instruction Fine-Tuning method or our use case because the data we had was more aligned to the prompt and response format. As mentioned, we had 50,000 prompt and response pairs. We stored the data in Unity Catalog and used the Databricks Foundation Model Training API.
Key Features of LLM Fine-Tuning
- Domain and linguistics adaptation
- Updated model
- Consistent and specific style in responses
Achieved Results in LLM Fine-Tuning
When compared to generic LLMs, the fine-tuning process enhanced the model by adapting it to the domain and adjusting its response style according to our preferences with less instruction required. Fine-tuned mistralai/Mistral-7B-v0.1, when compared to non-fine-tuned (generic) mistralai/Mistral-7B-v0.1, performed better in answer correctness (Refer Table 1 for detailed metrics).
Even though the accuracy metrics improved compared to the generic model, the accuracy of the results decreased compared to RAG, with answer correctness decreased from 51% to 49% when compared to generic RAG. The fine-tuned model has learned context from the training data, but still gives answers from the pre-trained knowledge. Even though the results are concise and styled similar to ground truth, we cannot use these answers as they contain a lot of irrelevant information.
Thus, the conclusion is that fine-tuned LLMs give more accurate answers when compared to using generic LLMs, but we cannot substitute RAG with just fine-tuning. RAG is ahead in accuracy metrics when compared with fine-tuned LLMs – and the fine-tuned LLM answers have new knowledge learned from training data, but the answers are not only contained to the content of the training data – hence making it unreliable to use.
Here are some examples of the results we achieved:
Question: "If I am changing my phone what is the right thing to do with my
Google Pay?"
Instruction Fine-tuned answer: "Download Google Pay on your new phone, sign in
with your Google account using the same mobile number, and add your cards."
Ground Truth: "You can delete all your cards one at a time in Google Pay. You
should also log out of the Google Pay app and uninstall the app."
Explanation: The given answer is not accurate. The answer provided is not fully
from the content provided in training data. It has more hallucination than RAG.
Section 3: LLM Fine-Tuning + Retrieval-Augmented Generation (RAG) on Databricks
In the previous section on LLM fine-tuning, we faced the issue of hallucination/going beyond the training data. Additionally, the model needs to be retrained whenever new data is added or updated within a specific domain. We needed something more than just fine-tuning. To address these challenges, we implemented RAG combined with LLM fine-tuning. We used instruction fine-tuning to fine-tune the LLM, then added RAG on top of it. We changed the LLM for generation in RAG from generic Mistral-7B to fine-tuned Mistral-7B.
There are multiple ways to combine Fine-tuning and RAG. We decided to go with RAFT. RAFT , or Retrieval Augmented Fine-Tuning, is a technique to make language models smarter for specific topics. It trains models to understand questions using related documents and give answers based on them.
In Fine-tuning + RAG, the model has learned the information from domain data and is specifically trained to perform RAG as a downstream task. The method to fine-tune is also different from the way we fine-tuned in Section 2. In this method, we also give retrieved context along with the question and answer in the training data. This helps the model to perform well in RAG-based downstream tasks.
Steps to Fine-Tune LLM on Banking Domain Dataset Using Databricks Foundation Model Training API
Step 1: Data Preparation
We have 50,000 FAQ pairs containing questions (Q) and answers (A), out of which 6,000 are unique FAQs. For the unique FAQs, we generated a new column (C) in the dataset, which created a chunk by combining the question and answer. For each question, we searched for the top-5 chunks (C) using embedding search. These top-5 chunks were provided as co ntext in the prompt along with the question. While training, in the prompt, top-5 chunks and the query are given, and in response, the answer is given.
Let’s see an example of the training data.
Supervised Fine-Tuning / Instruction Fine-Tune Example:
[{
"prompt": "You are a Bank QnA bot. Read and understand the user's query. Your task is
to provide a response generated from the given context only. Context: ([['All
Savings Bank Account holders are generally subject to charges. However, exemptions
apply to NRIs, Overdraft account holders, Prepaid and Travel Currency Card Holders.
These specific types of account holders do not have to pay charges, including SMS
charges, on their accounts.'], ['There are no additional charges imposed by the
Bank for the SMS alert facility. However, the Bank is not responsible for any extra fees
that may be charged by your service provider.'], ['For the SMS alert facility
provided by the Bank, there are no additional charges or fees imposed by the bank
itself. However, it is important to note that the Bank is not responsible for
any extra charges that may be levied by your service provider for this service.'],
['When receiving SMS notifications from the bank, you will be charged standard SMS
fees according to your mobile operator's rates. This applies to all types of alerts,
including updates and notifications, sent as text messages to your mobile phone.'],
['The Bank provides its customers with a free mobile banking application for
activation, downloading, and usage. There are no charges or fees imposed by the Bank
for using this application. However, your mobile operator may charge for GPRS/SMS
usage. It is advised to check with your operator for specific details on any
associated costs.']]). User Query: (Which account holders do not have to pay SMS
charges?) If no relevant information is found in the context then respond as: 'I am
a Bank bot, I only answer queries related to Bank.' Return response.",
"response": "All the Savings Bank Account holders would be charged except NRIs,
Overdraft accounts, Prepaid and Travel Currency Card holders."
}]
This one example out of the 6,000 from the training data. As you can observe here, we are training the model on domain-based data, along with this we are also training the model to perform well on RAG-based downstream tasks.
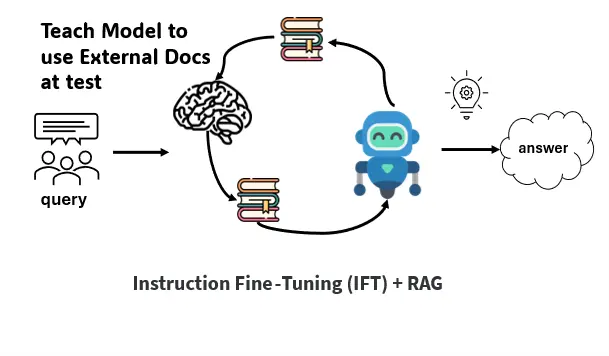
Figure 3: Diagram illustrating process of Fine-Tuning + RAG
Step 2: Upload the Data on Unity Catalog and Train the Model
Upload the prepared data on Unity Catalog and choose the Mistral AI model to work with from the list of models on Databricks. You need to load the weights of the pre-trained Mistral AI and make use of them in fine-tuning the existing model.
Follow the steps below:
1: Install the Required Package
First, ensure you have the databricks-genai package installed in your environment. You can install it using pip:
%pip install databricks-genai
2: Import the Fine-Tuning Module
Once the package is installed, import the fine-tuning module from databricks_genai:
from databricks_genai import finetuning as ft
3: Create a Fine-Tuning Run
Use the ft.create function to create a fine-tuning run. This involves specifying the model, paths to training and evaluation data, task type, registry location, evaluation prompts, training duration, and learning rate. Here is the complete code to set up the fine-tuning run:
run = ft.create(
model='mistralai/Mistral-7B-v0.1',
train_data_path='/Volumes/finetuningdbxllm/default/dbxft/train_data.jsonl',
eval_data_path='/Volumes/finetuningdbxllm/default/dbxft/test_data.jsonl',
task_type='INSTRUCTION_FINETUNE',
register_to='finetuningdbxllm.default',
eval_prompts=["Can I make part payment in the Saver account", "How can I claim for cashback"],
training_duration='30ep',
learning_rate='5e-7'
)
Explanation of Parameters:
model: The pre-trained model you want to fine-tune. In this case, it is 'mistralai/Mistral-7B-v0.1'.
train_data_path: The file path to your training data in JSONL format.
eval_data_path: The file path to your evaluation data in JSONL format.
task_type: The type of fine-tuning task. Here it is 'INSTRUCTION_FINETUNE'. You can select "CONTINUED_PRETRAIN" or "CHAT_COMPLETION" according to the data input format.
register_to: The registry location where the fine-tuned model will be registered.
eval_prompts: A list of evaluation prompts to test the fine-tuned model.
training_duration: The duration of the training process, specified as '30ep' (30 epochs).
learning_rate: The learning rate for the fine-tuning process.
4: Execute the Fine-Tuning Run
Following the completion of fine-tuning configuration (as outline previously), initiate the training process. Upon execution, the system you can check the running job name and its current status.
5: Check Execution Status
status = ft.get_events('ift-mistral-7b-v0-1-wphvt1') # Change the run id here accordingly

Figure 4: Execution status
Step 3: Trace the Model in Experiment
Trace the run name in experiments, check the model metrics, and training status.
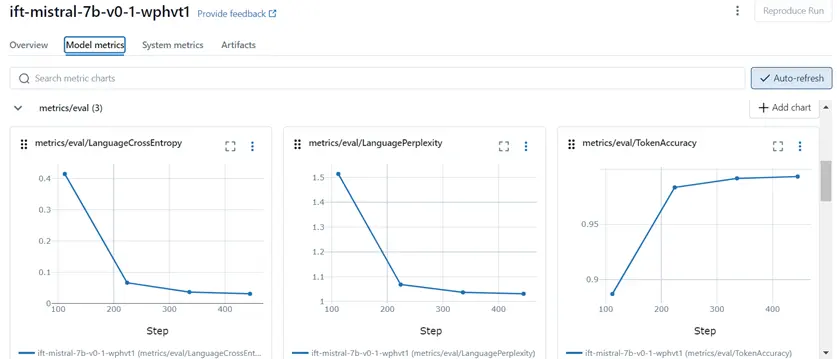
Figure 5: Trace the model metrics
Step 4: Serving Model
After finishing the training status of the model, check the same model on the registry location. Click on it and serve the model.
Figure 6: Serve the model
Step 5: Execute the Query Endpoint
After serving the model successfully, go to the Serving and check the serving endpoint. Click on Query endpoint to get the inference from the trained fine-tuned model. As mentioned in data preparation step, while inference as well, we provide top-5 chunks in the context for the implementation of RAG+Fine-tuning.
Achieved Results
After using RAFT fine-tuning, we achieved significant improvements. Our model now gives better answers because it understands the context better. It’s also become better at staying relevant even when we add or update new data and reduces hallucinations. We improved the answer correctness from 51% with generic RAG to 75% with fine-tuned RAG. Refer the accuracy metric in Table 1 for more understanding.
Here are some examples of the final results we achieved:
Question: "If I am changing my phone what is the right thing to do with my Google Pay?"
Answer: "You can either:
* Delete all your cards one by one from Google Pay.
* Log out of Google Pay.
* Uninstall the Google Pay app from your phone."
Explanation: "As you can see, the answer was correct and well-formatted (in markdown),
and the exact response."
When tested on multiple questions, the results achieved here are better than both the fine-tuned model and generic RAG. There was significant accuracy increase when compared to RAG as well. The amount of time spent in prompting the generic RAG was also reduced in this method.
Accuracy Metric: Comparing Generic LLM, Fine-tuned LLM, Generic LLM + RAG, Fine-tuned LLM + RAG
To test the hypothesis of better accuracy, we also performed tests for all the variations of the Mistral model. We tested using Ragas score – metrics designed to test the accuracy on RAG-based systems.
We compared generic/non-fine-tuned Mistral to Fine-tuned Mistral, RAG, and Fine-tuned Mistral + RAG to find the incremental increase in accuracy due to each step. We used four metrics to compare the scores.Answer correctness increased from 51% while using the Mistral 7B + RAG model to 75% with the Fine-tuned Mistral 7B + RAG model.
Here is the detailed meaning of the metric we used to measure the accuracy of the system.
- Answer Correctness: It involves gauging the accuracy of the generated answer when compared to the ground truth. This evaluation relies on the ground truth and the answer.
- Answer Relevancy: This metric is computed using the question, the context, and the answer. A lower score is assigned to answers that are incomplete or contain redundant information whereas higher scores indicate better relevancy.
- Answer Semantic Similarity: It pertains to the assessment of the semantic resemblance between the generated answer and the ground truth. This evaluation is based on the ground truth and the answer.
- Faithfulness: This measures the factual consistency of the generated answer against the given context. It is calculated from answer and retrieved context. The answer is scaled to (0,1) range. Higher the better.
| Metric | Mistral 7b instruct | Finetuned Mistral 7b | Mistral 7b instruct + RAG | Finetuned Mistral 7b + RAG |
|---|---|---|---|---|
| Answer Correctness | 0.36252584 | 0.4951 | 0.516458035 | 0.7594 |
| Answer Relevancy | NA | NA | 0.858136863 | 0.8991 |
| Answer Semantic Similarity | 0.865035498 | 0.8524 | 0.880681273 | 0.9396 |
| Faithfulness | NA | NA | 0.900110591 | 0.9216 |
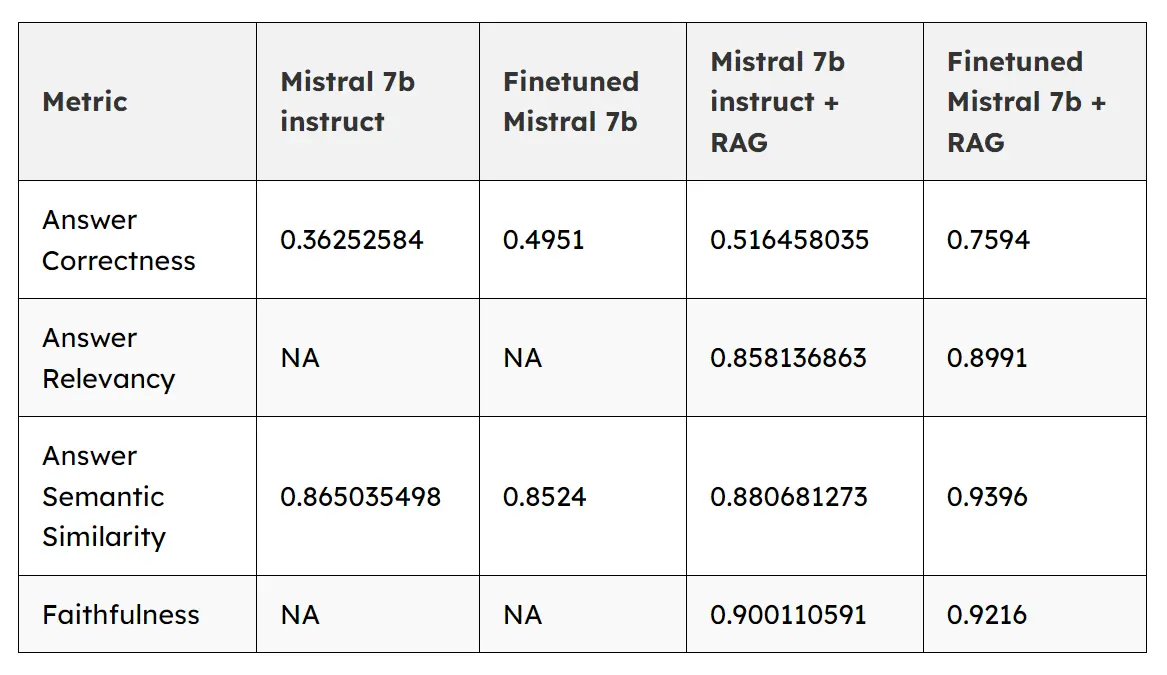
It is quite evident from the metric as well that merging RAG and fine-tuning can be the best of both worlds and can result in more accuracy in domain-specific scenarios.
- Key Features :
- 1. Compared to generic Mistral RAG, our fine-tuned RAG gives accurate numbers in responses.
- 2. Better responses in cases where Mistral RAG fails to understand the query.
- 3. More understanding of bank products and services.
- 4. Fine-tuned RAG provides consistent and specific style in responses.
- 5. Provides URL links wherever necessary.
- 6. Precise and concise responses.
- 7. Fine-tuned RAG knows the format, so it does not include any extra unuseful words in responses hence it works better than Mistral RAG.
Conclusion: Harnessing the Power of Fine-Tuned Language Models!
From all the comparisons made above, it is clear that fine-tuning significantly improves the accuracy of Large Language Models (LLMs) for the given domain information. Specifically, by comparing the results of different models, the Fine-tuned Mistral 7B + RAG model is more accurate, it generates responses that are relevant and reliable, and provides answers that are accurate and semantically appropriate to the context of the question.
Fine-tuning also enables smaller models (Mistral 7b in our case) to perform as well as large models (Mixtral 8x7B) on the domain it has been trained. Hence, it helps in improving latency and throughput, and also saving a lot in compute resources.
It is highly recommended to spend time fine-tuning your LLMs, and use this as the starting point for your RAG system. This will help you get the most out of your models in your particular domain areas of interest.
At the end of this blog, I am attaching a few inference results comparing both kinds of RAG.
Question: "What is the limit of POS transactions I can make with the Debit
Card each day?"
Ground truth: POS Limit per day: INR 5,00,000. To get information, click [here](https://
www.ABCBank.com/retail/cards/cards/debit-card).
Generic RAG: "The limit of POS transactions you can make with the Business Debit Card
each day is INR 5,00,000."
Fine-tuned RAG: "Business Debit Card: POS Limit per day: INR 5,00,000. To get
information, click [here](https://www.ABCBank.com/retail/cards/cards/
debit-card)."
-----------------------------------------------------------------------------------------------------------------------
Question: "What is the transaction fee incurred for swiping my forex card?"
Ground truth: No, there is no transaction fee incurred for swiping your Forex Card for
payments at merchant establishments.
Generic RAG: "The transaction fee incurred for swiping a Forex card at retail stores or
merchant establishments is no additional fee or transaction charges. Please note that
the information provided is only based on the information present in the given
database. If you have any other specific queries or concerns, please let me know."
Fine-tuned RAG: "There is no transaction fee incurred for swiping your ABC Bank Forex Card for payments at merchant establishments."
Ready to transform your customer support with the power of Fine-Tunned LLM? Contact us today at enterprisesales@celebaltech.com to explore how Databricks and fine-tuned LLMs can elevate your customer experience!